论文阅读 PartialFed: Cross-Domain Personalized Federated Learning via Partial Initialization
1. 背景 & 动机
联邦学习是一种以隐私保护方式进行分布式机器学习的范式。在参数服务器的训练架构下,客户端的数据将保存在本地而不上传到服务器中。在这种情况下,每个客户端的本地数据很可能是异构的(例如非独立同分布),这导致了使用联邦平均算法(FedAvg)训练出的全局模型存在准确率下降等问题。为了应对客户端之间的数据高度异构情况,近年来提出的个性化联邦学习引起了多数学者的兴趣。所谓个性化联邦学习,就是根据客户端本地数据分布的特点,为不同客户端提供一个本地模型而不是直接使用统一的全局模型。
2. 方法
得益于一些在multi-domain learning以及multi-task learning的研究,本文提出在训练过程中客户端使用 ”全局模型+本地模型“的混合初始化代替以往的 ”全局模型“ 初始化方式,以此达到客户端可以在契合本地数据分布的情况下,有选择性的初始化本地模型进行后续训练。图 1 展示了这一流程:
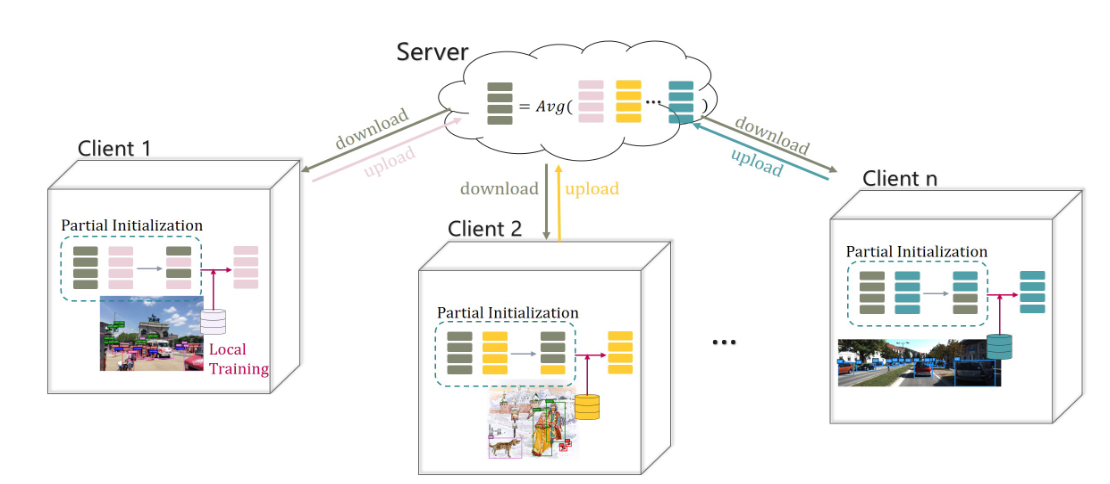
在l联邦学习的每个迭代中,中心服务器会将全局模型发送给所有的客户端。然后,每个客户端将通过部分初始化将服务器的全局参数与自身的局部参数混合起来,用于下一次的局部训练。
2.1 PartialFed-Adaptive
作者提出了两种方式,一种是依据人类专家知识的方式手动选择哪些全局参数需要被读取,但是这种方式是很低效率的。因此,这里提出了一种能够自适应选择参数的算法。具体来说,我们需要优化一下目标: \[ \min _{A_{t}^{c}} \min _{W_{t}^{c}} L_{\text {train }}\left(D_{c}, W_{t}^{c} \mid W_{t, \text { init }}^{c}=A_{t}^{c}\left(W_{t}, W_{t-1}^{c}\right)\right) \] 其中,\(A_{t}^{c}\) 是初始化策略(也就是如何选择),它是一个大小为 [k, 2] 的向量,k 是神经网络的层数。其中的每个元素 \(\alpha_{t}^{c} \in A_{t}^{c}\) 为 0 或 1,同一行的元素之和为 1,1 表示需要读取这一层神经网络的参数。\(W_{t}^{c}\) 是待优化的本地模型,\(W_{t, init}^{c}\) 是混合后的本地初始化模型, \(W_{t}\) 是全局模型,\(W_{t-1}^{c}\) 是上一轮本地模型。\(D_{c}\) 客户端的本地数据。
由于初始化策略 \(A_{t}^{c}\) 做的是离散决策,因此这里无法使用反向传播算法进行优化。为了解决这问题,作者使用重参数化技巧(Gumbel-Softmax),将离散向量转换成连续向量,如下图所示:
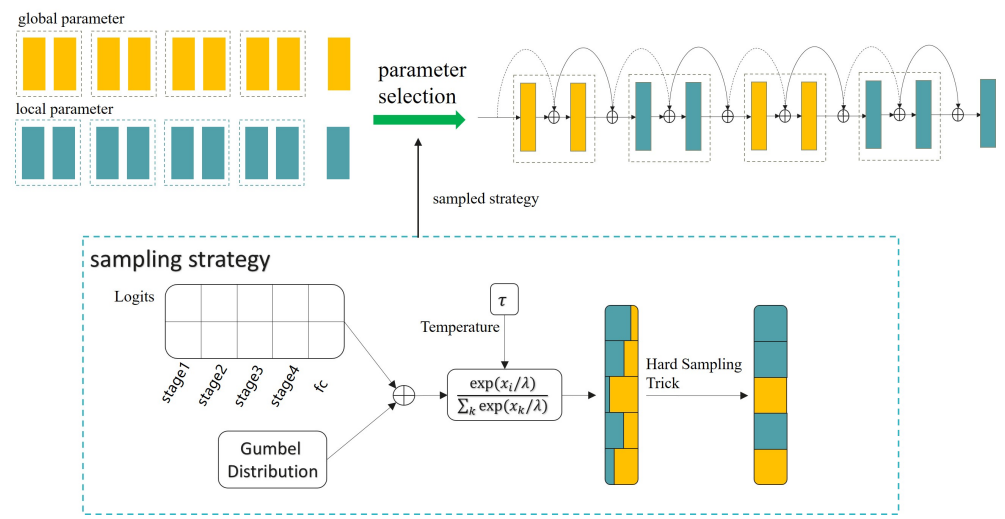
采样策略由四个步骤组成。
从 Gumbel 分布中取样;
将取样值添加到未归一化策略 logits 中,控制加载全局和局部参数的概率;
通过带温度控制的 softmax 得到一个软策略;
使用硬取样技巧将软策略离散化。采样后的策略被用来混合全局和局部参数。最后,合并后的参数用于ResNet-18 的前向传递。整个过程是可分的,实现了端到端的训练。
2.2 训练流程
整个训练流程总结在图3的算法描述中。模型参数 \(W_{t}^{c}\) 和策略参数 \(A_{t}^{c}\) 通过 EM 算法进行迭代更新。更新频率表示为 \(f_m\) 和\(f_s\)。在每个训练步骤中,通过 Gumbel-Softmax 对一个离散的批处理策略进行采样,用以混合全局和局部参数。混合后的参数用于计算损失,并在每个训练步骤中交替更新自身参数 \(W_{t}^{c}\) 和策略参数 \(A_{t}^{c}\) 。公式中的温度参数 \(\tau\) 被初始化为 5.0,并逐步退火接近 0。因此采样策略也会不断接近原始离散分布,在 \(\tau\) 接近零极限的时候。

3. 实验
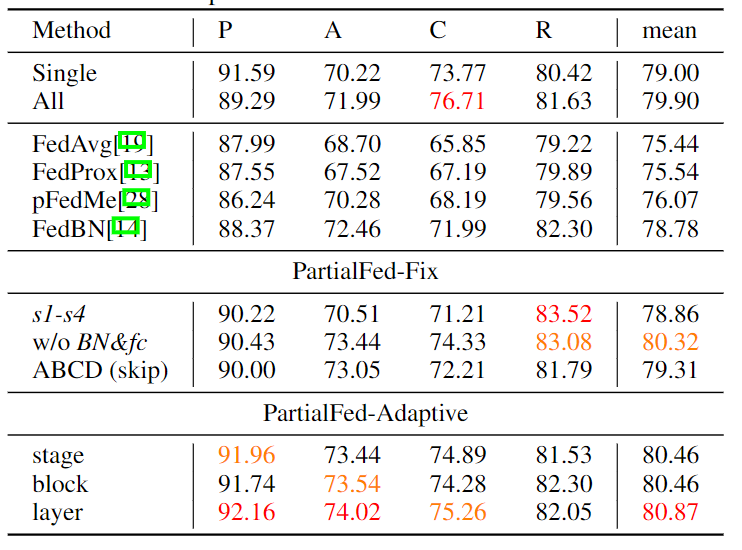
在 Office-Home 数据集上进行跨域图像分类,共 65 类物体。此外共有 4 个域,每个域平均有 3k 张图片。
如图 4 所示,平均而言,它比原始FedAvg 和 FedBN 分别提升了 5.43% 和 2.09%。
4. 总结
文中展示了一种简单而新颖的个性化联邦学习方法。方法的核心是混合初始化,它部分地利用了 FedAvg 给出的全局模型参数。受前人工作的启发,作者开发了一套手动的混合策略,并验证了它们的可靠性。更进一步,作者开发了一个基于数据感知的策略,它是通过模型参数自适应学习的。实验表明,所提出的两种策略,PartialFed-Fix和 PartialFed-Adaptive,在包括物体分类和检测在内的跨域联邦实验中的表现超过了一系列最先进的方法。
虽然自适应学习策略在学习客户端特定的策略方面具有优势,它可以缓解客户端由于数据分布变化引起的负面影响。但是,它也有不完全训练的风险,要么欠拟合,要么过拟合。例如,文中发现在一个50层的 ResNet 上搜索策略变得很难训练。 如何提高策略学习的效率与神经结构搜索(NAS)有关,它考虑了探索和利用之间的平衡。基于数据感知的方法也忽略了元信息,如数据集的基数。解决这个问题的一个可能的方法是将人类的先验纳入自适应算法,这是由 PartialFed-Fix 和 PartialFed-Adaptive 组合而成的。