ubuntu下安装hadoop, hbase
安装环境以及软件版本:
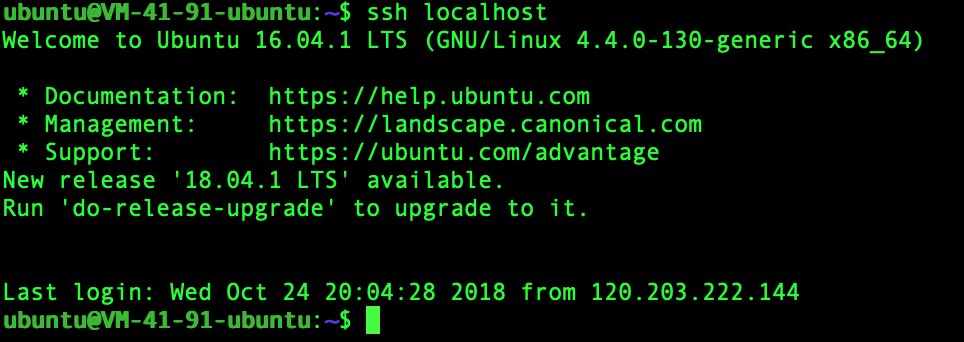
由于 Hadoop 需要在一台或多台计算机上的多个进程之间通信,我们需要确保正在使用 Hadoop 的用户不输人密码即可连接到所需的每台主机。通过创建有一个空口令 Secure Shell (SSH)的密钥对来实现这一点。我们使用 ssh -keygen 命令启动这一进程,并接受所提供的缺省设置。
一旦创建了密钥对,需要将新生成的公钥添加到可信密钥的存储列表。这就意味着,当试图连接这台机器时,公钥会被信任。然后,使用 ssh 命令连接本地机器,应该会获得一个如上述显示的关于信任主机证书的警告。确认后,我们应该能够连接而不再需要密码或出现提示。
1 | sudo apt-get install openssh-serve |
之后
1 | cat ./id_rsa.pub >> ./authorized_keys # 加入授权 |
安装 Java11
首先从oracle官网下载对应的java版本,这里我选择的是jdk-11.0.1_linux-x64_bin.tar.gz

1 | mkdir /usr/lib/jvm # 创建jvm文件夹 |
在.bashrc文件添加以下内容
1 | export JAVA_HOME=/usr/lib/jvm/java |
1 | source ~/.bashrc #使新配置的环境变量生效 |
输出这个说明配置成功

安装Hadoop 2.9.1
下载hadoop-2.9.1.tar.gz,之后执行以下步骤
1 | sudo tar -zxvf hadoop-2.9.1.tar.gz -C /usr/local #解压到/usr/local目录下 |
给hadoop配置环境变量,将下面代码添加到.bashrc文件:
1 | export HADOOP_HOME=/usr/local/hadoop |
执行source ~./bashrc使设置生效,并查看hadoop是否安装成功

安装Hbase 1.4.8
下载hbase-1.4.8-bin.tar.gz,之后执行以下步骤
1 | sudo tar -zxvf hbase-1.4.8-bin.tar.gz -C /usr/local # 解压到/usr/local目录下 |
给hadoop配置环境变量,将下面代码添加到.bashrc文件:
1 | export PATH=$PATH:/usr/local/hbase/bin |
执行source ~./bashrc使设置生效,并查看hbase是否安装成功

hadoop伪分布式配置
Hadoop运行的3 种模式
在 Hadoop 上运行作业,却回避了一个重要的问题:应该在何种模式下运行 Hadoop? Hadoop 有 3 种运行模式,各种模式下,Hadoop 组件的运行场所有所不同。回想一下,HDFS 包括一个 NameNode,它充当着集群协调者的角色,是一个或多个用于存储数据的 DataNode 的管理者。对于 MapReduce 而言,JobTracker 是集群的主节点,它负责协调多个 TaskTracker 进程执行的工作。Hadoop 以如下 3 种模式部署上述组件。
- 本地独立模式:如果不进行任何配置的话,这是 Hadoop的默认工作模式。在这种模式下,Hadoop 的所有组件,如 NameNode、DataNode、JobTracker 和 TaskTracker,都运行在同一个 Java 进程中。
- 伪分布式模式:在这种模式下,Hadoop 的各个组件都拥有一个单独的 Java 虚拟机,它们之间通过网络套接字通信。这种模式在一台主机上有效地产生了一个具有完整功能的微型集群。
- 完全分布式模式:在这种模式下,Hadoop 分布在多台主机上,其中一些是通用的工作机,其余的是组件的专用主机,比如 NameNode 和 JobTracker。
这里进行的是伪分布式模式配置
1 | cd /usr/local/hadoop/etc/hadoop/ |
修改core-site.xml,临时目录tmp手动创建
1 | <configuration> |
修改hdfs-site.xml,name目录和data也手动创建
1 | <configuration> |
在伪分布式模式中,首次启动Hadoop需要格式化hdfs系统
1 | hadoop namenode -format |
注意: 格式化 NameNode 的命令可以执行多次,但是这样会使所有的现有文件系统数据受损。只有在 Hadoop 集群关闭和你想进行格式化的情况下,才能执行格式化。但在其他大多数情况下,格式化操作会快速、不可恢复地删除 HDFS 上的所有数据。它在大型集群上的执行时间更长。所以一定要小心。
启动hadoop
1 | cd /usr/local/hadoop/ |
输入
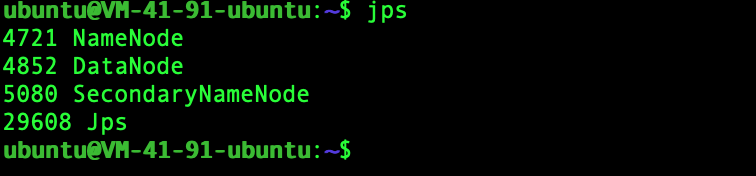
1 | jps |
出现如下进程,说明启动成功