[论文笔记] Gossip Learning
提出 Gossip Learning,与 Federated Learning 做比较,实验表明使用 Gossip Learning 训练的模型在一定时间过后与Federated Learning 表现相当。
原文地址
特色
传统的 Federated Learning 是 master-worker 架构(master 节点负责模型聚合,worker 是边缘设备,不同于参数服务器架构)
Gossip Learning 同样主张将数据保留在边缘设备上,但是它没有负责聚合的服务或者任何的中心组成部分,也就是说它是去中心化的。
文章通过实验表明了这两种方法训练出的模型变现相当,在高压缩率(采样率低)情况下,Gossip Learning 表现更佳。
过程
Federated Learning
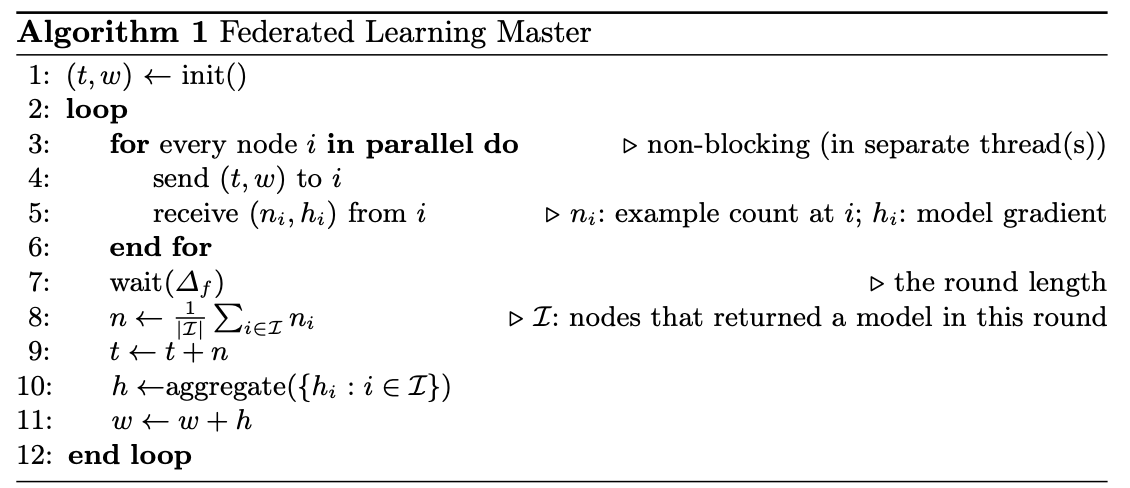
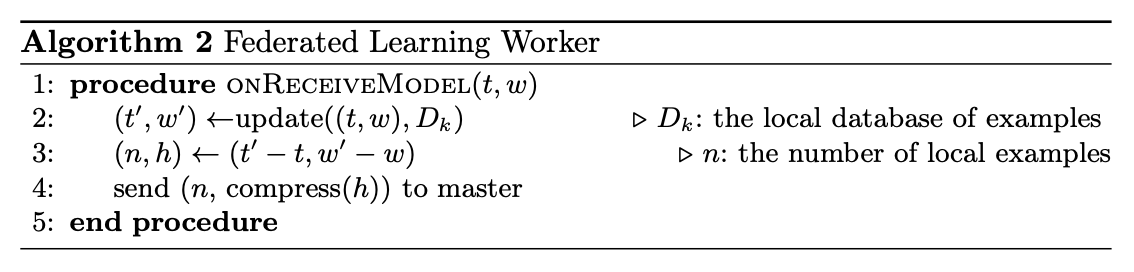
worker 节点训练过程是异步的,master 在给定的时间 \(\Delta_f\) 内收集来自 worker 的参数信息,超过 \(\Delta_f\) 仍未发送信息的worker 将被抛弃。算法第 10 行使用了压缩机制。
master 节点运行的算法:
worker 节点运行的算法:
Gossip Learning
Gossip Learning 的特点是没有中心节点,每次更新的时候使用一种采样方式[参考文献 1, 2]从相邻节点获取模型参数 \(w_r\) 并合并到本地模型中,随后使用本地数据 \(D_k\) 更新。

模型压缩以及聚合
模型压缩:
- 不压缩
- 随机选取大小为 s 的模型参数

模型聚合:
- 简单的平均
- 基于采样进行聚合

模型参数更新:

实验
基于不同采样率在 Spambase Dataset 上的实验结果。
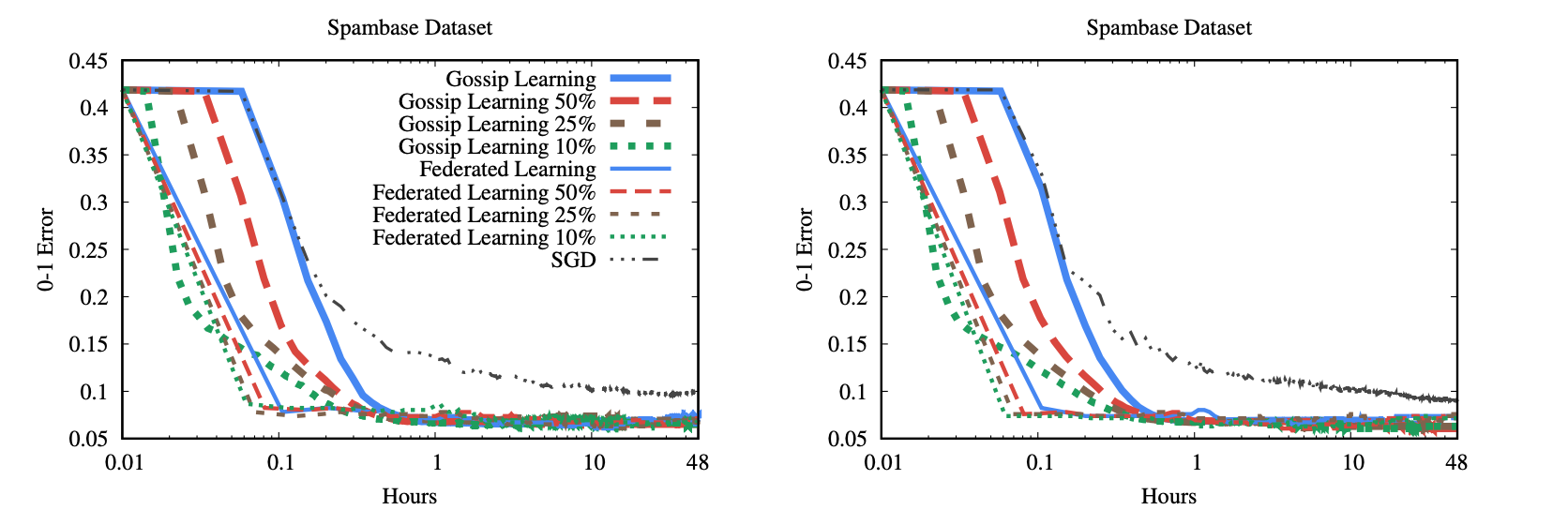
还有其他实验结果就不一一列举了。
结论
文章的目标在模型学习效率上进行对比,在统一分配的情况下,Gossip Learning 和 Federated Learning 效率差不多,在高压缩率下,Gossip Learning 表现更好。
未来工作的方向是设计一种针对 Gossip Learning 和 Federated Learning 的模型评估,以及更复杂的压缩技术。
参考文献
- Jelasity, M., Voulgaris, S., Guerraoui, R., Kermarrec, A.M., van Steen, M.: Gossip-based peer sampling. ACM Trans. Comput. Syst. 25(3), 8 (2007)
- Roverso, R., Dowling, J., Jelasity, M.: Through the wormhole: low cost, fresh peer sampling for the internet. In: Proceedings of the 13th IEEE International Conference on Peer-to-Peer Computing (P2P 2013). IEEE (2013)