[论文笔记] Edge-Assisted Hierarchical Federated Learning withNon-IID Data
提出了一种分层的联邦学习以及对应算法(HierFAVG)降低通信延时问题,与传统的 FAVG(Federated Averaging) 做对比。
原文地址
Edge-Assisted Hierarchical Federated Learning withNon-IID Data
背景
将 ML 或 DL 模型应用在边缘设备上是一个革命性的突破。然而,传统的模型训练是在计算中心完成的,近几年出于隐私保护问题,用户数据将不会上传至计算中心,数据保留在用户手中。在不上传数据的情况下,FL (联邦学习)提出了让各个设备协同训练一个共享模型,然后上传模型的更新信息到云中心进行模型聚合。但是,这种做法在通信消耗上出现了瓶颈。
过程
分层结构如下:
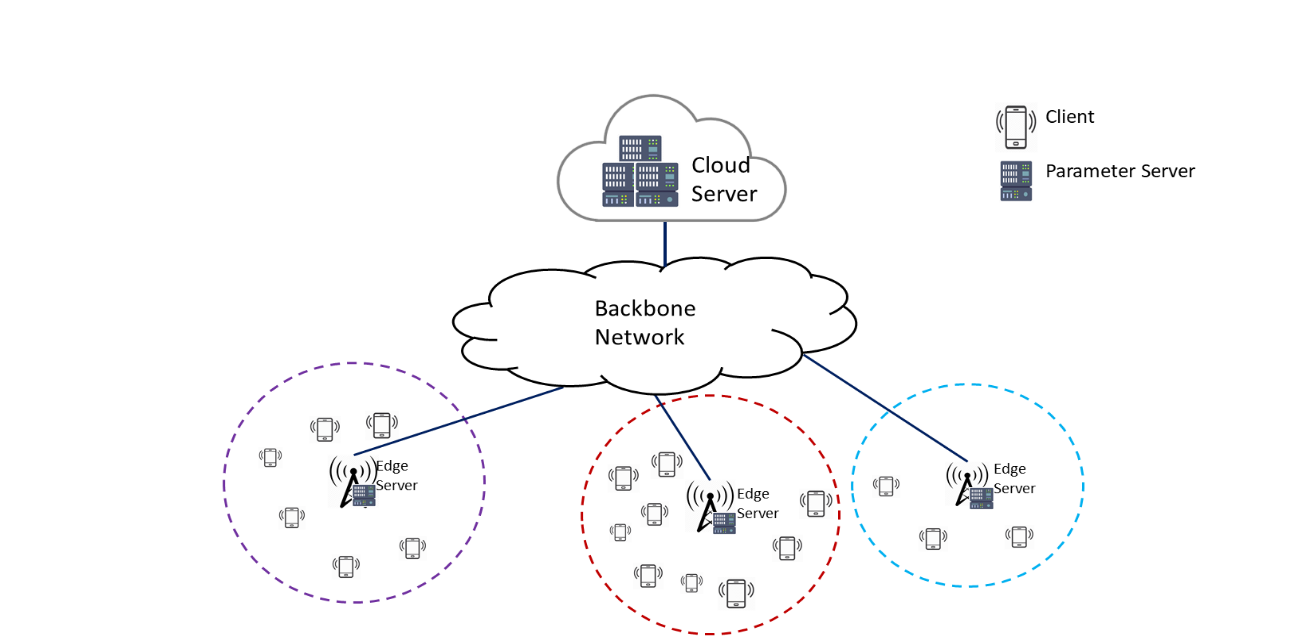
客户端的更新参数不是直接发送至云中心,而是发送至边缘服务器,然后边缘服务器再发送至云中心。
原因如下:
- 云中心比边缘服务器能够处理更多的用户连接,能够处理大量数据进行模型聚合。
- 客户端与边缘服务器的通信延时更低。
HierFAVG 算法过程
客户端每经过 \(\tau_1\) 轮的更新就在边缘服务器上进行模型聚合操作,边缘服务器每经过 \(\tau_2\) 轮的聚合就在云中心进行模型聚合。也就是说每经过 \(\tau_1 \tau_2\) 轮的更新就与云中心通信。
我们记 \(\mathcal{w}_i^l(t)\) 为第 t 轮本地更新的模型参数,那么有:
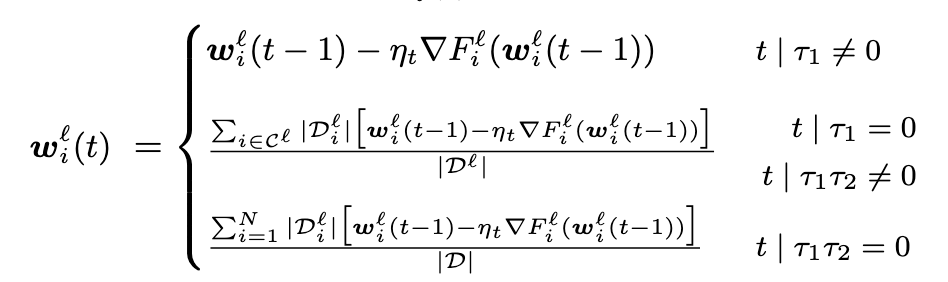
算法过程如下:

实验结果
\(T_\alpha\) 表示达到准确率 \(\alpha\) 需要的时间
\(N_\alpha\) 表示达到准确率 \(\alpha\) 需要的通信次数
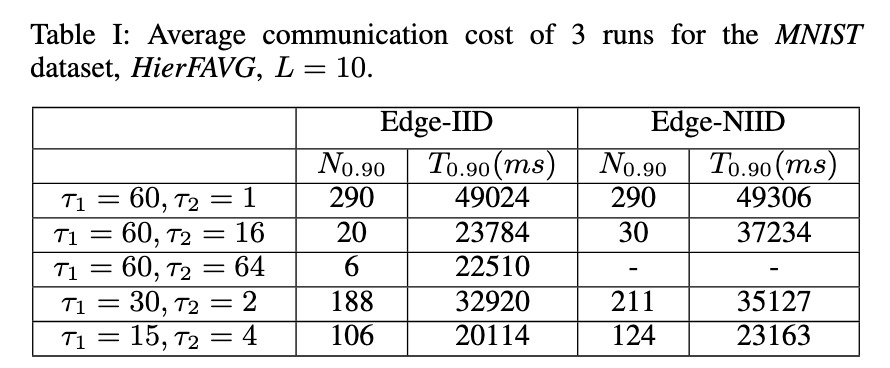
如上表所示,当 \(\tau_1 \tau_2\) 固定为 60 的时候,无论是 Edge-IID 还是 Edge-NIID,与云中心的通信次数都随着 \(\tau_1\) 的减少而减少。这是因为随着 \(\tau_1\) 的减少模型的收敛速度更快了,如图1所示。
同时实验也表明了通过适当的增加 \(\tau_2\) 可以降低与云中心的通信次数。但是这对于NIID不是那么使用,当 \(\tau_1=60, \tau_2 = 64\) 的时候,模型无法收敛到预期精度。
总结
文章提出了一种分层的联邦学习体系结构,并辅以训练算法 HierFAVG。对于两个云模型聚合之间相同数量的本地更新,优先选择较小的边缘聚合间隔 \(\tau_1\) 。 此外,当边缘云之间的数据分布为 IID 时,可以通过增加 \(\tau_2\) 来减少通信开销。 尽管研究表明在选择 \(\tau_1, \tau_2\) 值时需要权衡取舍,但仍需进一步研究以充分表征和优化这些关键参数。