torch.distributed 中 Collective functions 的使用方式
Pytorch中的分布式包(torch.distributed)可以帮助研究人员或者从业人员轻松地跨进程或在计算机集群中实现并行计算。
torch.distributed支持三种后端,分别是gloo, nccl以及mpi。 不同的后端对应的功能不一样,可以根据实际情况选择。
环境准备
为了展示这几个函数的使用,我们这里通过 docker 创建三个容器模拟真实物理机,镜像使用的是 pytorch/pytorch。
使用下面命令创建三个 docker 容器:
1 | docker run -it --name device1 -v [这里填写项目的绝对路径]:/root pytorch/pytorch |
这里需要开三个终端,每个终端对应一个容器。-v 参数是为了将本地目录映射到容器中,方便管理文件。如下图所示,我们创建了三个容器。
然后需要获取三个容器的 ip 地址,使用下面的命令可以获取相应容器的 ip 地址:
1 | docker inspect 容器ID | grep IPAddress |
在我的电脑上device1,device2,device3对应的 ip 地址分别是:
1 | 172.17.0.2 |
我们指定 ip 地址为 172.17.0.2 的容器为 rank=0,初始化方法使用 tcp,main 函数代码如下:
1 | if __name__ == '__main__': |
Collective functions
在 pytorch 中目前有六种 Collective functions ,分别是 Scatter,Gather,Reduce,All-Reduce,Broadcast,All-Gather。来看看官网的一张图就可以直观的认识到这几个函数的作用。
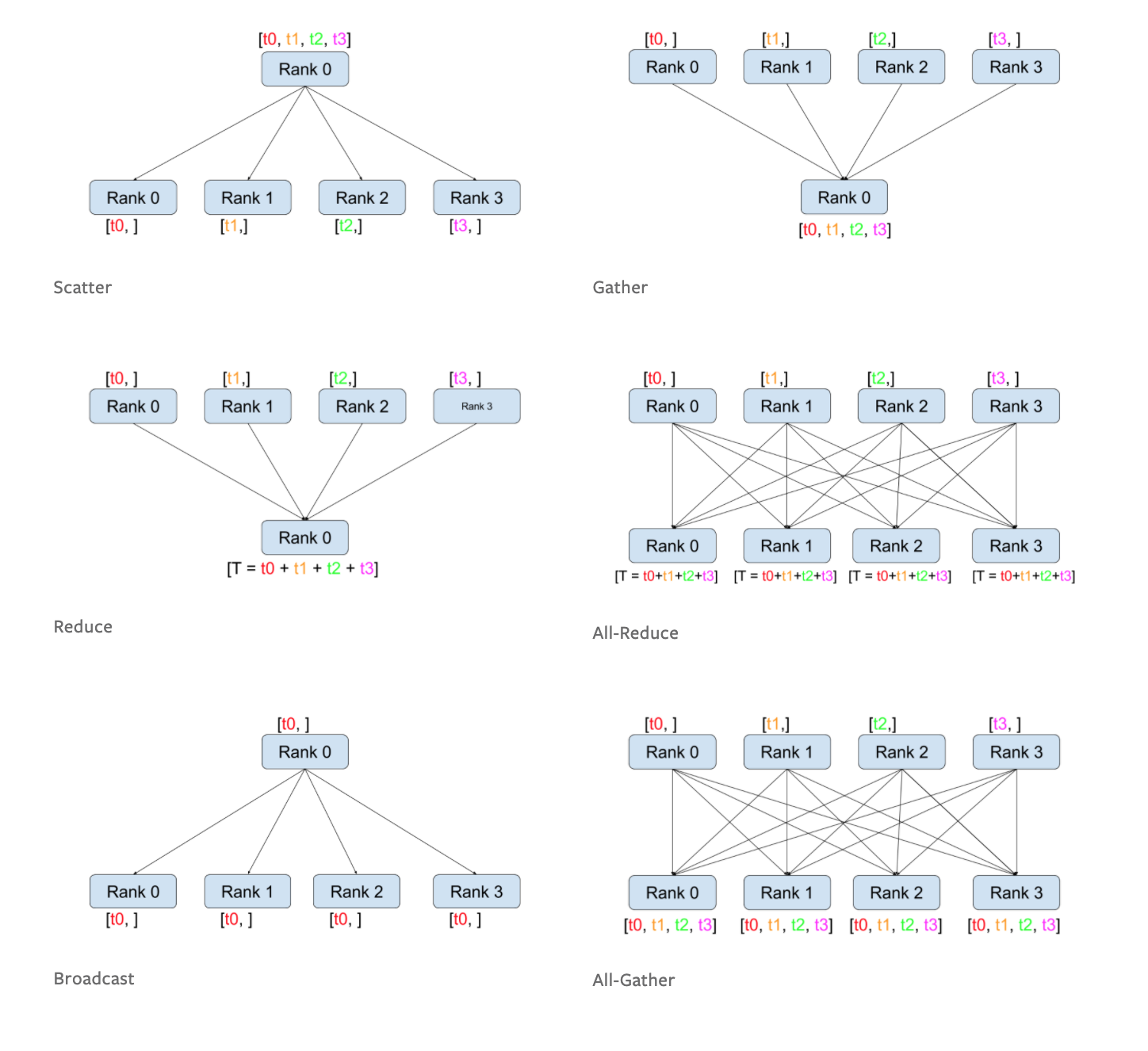
scatter
torch.distributed.scatter(tensor, scatter_list=None, src=0, group=\<object object\>, async_op=False)
这个函数的功能是将 scatter_list 列表中的第 i 个张量(tensor)发送到第 i 个进程中。代码如下所示:
注意:如果是接收方,那么scatter_list=[]
1 | import torch |
device1运行指令 python test.py --rank 0 --world_size 3,device2 运行命令 python test.py --rank 1 --world_size 3,device3 运行命令 python test.py --rank 2 --world_size 3。结果如下:
1 | [tensor([-1.2237]), tensor([-0.0276]), tensor([-0.9581])] |
gather
torch.distributed.gather(tensor, gather_list=None, dst=0, group=\<object object\>, async_op=False)
将所有进程的 tensor 值拷贝到 rank=dst 的进程中。代码如下:
1 | import torch |
结果如下:
1 | [tensor([0.]), tensor([0.5088]), tensor([1.3696])] |
reduce
torch.distributed.reduce(tensor, dst, op=ReduceOp.SUM, group=\<object object\>, async_op=False)
将 tensor 发送到 dst 并执行相应的 op 操作。
其中的 op 操作有:
- SUM
- PRODUCT
- MIN
- MAX
- BAND
- BOR
- BXOR
代码如下:
1 | import torch |
结果如下:
1 | tensor([0.7700]) |
后面的就不写样例展示了,知道了函数的功能之后相信大家都能够写得出来。
Broadcast
torch.distributed.broadcast(tensor, src, group=\<object object\>, async_op=False)
将 tensor 从 src 发送到所有的进程
All-Reduce
torch.distributed.all_reduce(tensor, op=ReduceOp.SUM, group=\<object object\>, async_op=False)
跟 reduce 的功能一样,只不过它是所有的进程都会进行 reduce 操作。
All-Gather
torch.distributed.all_gather(tensor_list, tensor, group=\<object object\>, async_op=False)
跟 gather 的功能一样,只不过它是所有的进程都会进行 gather 操作。
最后
其实代码可以再简洁点,可以使用 torch.multiprocessing 包,就不需要使用 docker 模拟了。然后 main 函数改为:
1 | import torch.multiprocessing as mp |